Z dwóch poprzednich wpisów dowiedzieliśmy się jak skonfigurować lokalne środowisko oraz czym jest Elastic Stack. Dziś dowiemy się jakie narzędzia przydadzą nam się zarówno do nauki Elasticsearcha, jak i w codziennej, produkcyjnej pracy z nim.
Kibana Dev Tools
Początkowo, wraz z niniejszym cyklem, miałem zamiar rozwijać testową aplikację/skrypt, która komunikowałaby się z Elasticsearchem i prezentowała konkretne, omawiane tu zagadnienia. Nie chciałem jednak korzystać z żadnego fluent API, czy innego wysokopoziomowego klienta, bo mogłoby to zaciemniać obraz tego co i gdzie jest wysyłane. Kiedy na prezentacji Dominiki i Patryka zobaczyłem co można zrobić w narzędziach deweloperskich Kibany, wiedziałem, że sprawdzą się tutaj idealnie.
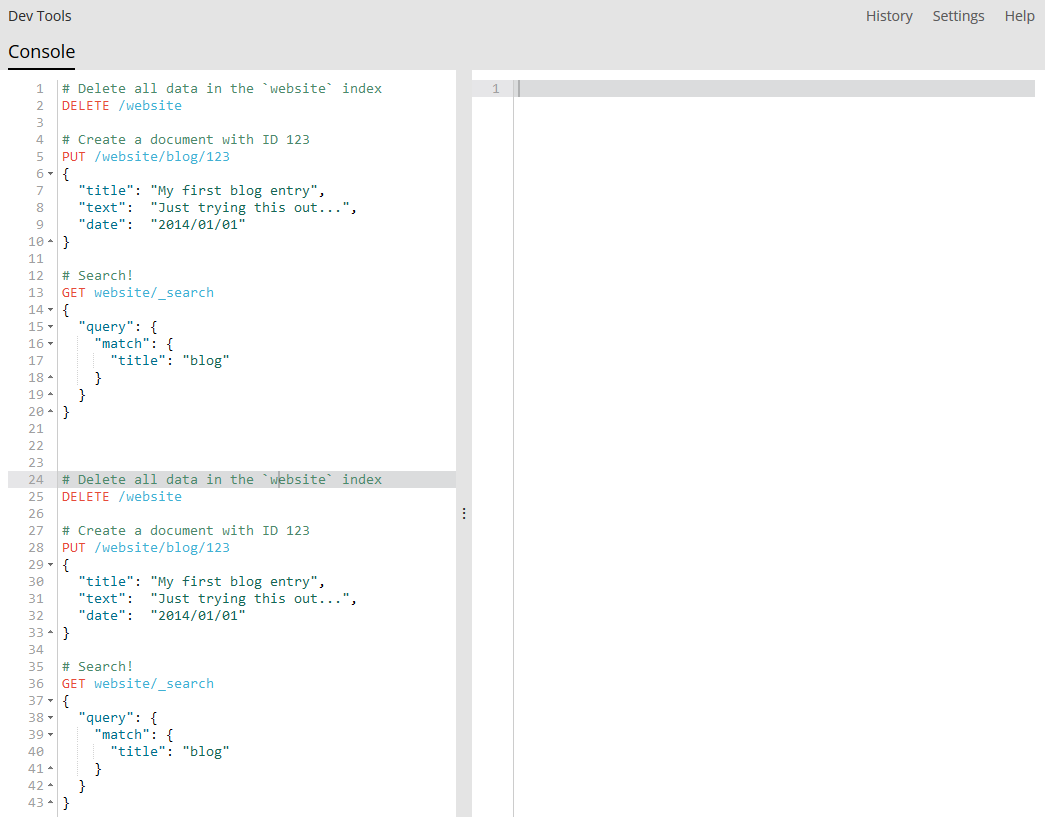
Konsola w Kibana Dev Tools
Podpowiadanie składni zapytań, endpointów, czy automatyczne formatowanie JSON-ów będzie dla nas bardzo pomocne. Jednocześnie, patrząc na powyższy zrzut ekranu, łatwo zauważyć przejrzystość tego rozwiązania – od razu widać co, gdzie i jak wysyłamy. Pozostanie tylko odpowiedzieć „dlaczego?” 🙂
Samą Kibanę już znamy. Jej instalacja i uruchomienie są zupełnie analogiczne do instalacji i uruchomienia Elasticsearcha prezentowanych w pierwszym wpisie tego cyklu. Krótką instrukcję obsługi narzędzi znajdziemy w dokumentacji Kibany. Konsolę widoczną powyżej dostajemy od razu po instalacji. Profiler i Grok Debugger dostępne są po instalacji X-Packa w Kibanie.
ElasticSearch Head (Chrome Extension)
Kibana jest dosyć ciężka. Niby 400 megabajtów po rozpakowaniu jakoś nie straszy, ale 46 tysięcy plików może zdziwić 🙂 Czasami możesz nie mieć potrzeby albo możliwości zainstalowania jej tylko po to, żeby skorzystać z narzędzi deweloperskich. W takim przypadku warto rozważyć instalację rozszerzenia do przeglądarki Chrome o nazwie ElasticSearch Head. Rozszerzenie opakowuje aplikację o tej samej nazwie, która może być również uruchomiona jako niezależny serwis lub jako plugin do Elasticsearcha (do wersji 2.x).

ElasticSearch Head
Oprócz odpalania zapytań ElasticSearch Head daje też ogólny pogląd na cały serwer Elasticsearch, na rozkład shardów i replic na poszczególnych węzłach, czy na poszczególne indeksy znajdujące się na naszym serwerze. Całkiem po(d)ręczne narzędzie.
Luke: Lucene Toolbox Project
Ostatnim omawianym dziś narzędziem, które może nam się przydać, jest Luke. Nie jest on związany wyłącznie z Elasticsearchem, ale z tym co znajduje się pod spodem, czyli z biblioteką Apache Lucene. Wspominałem już kiedyś, że to właśnie z jej udziałem został zbudowany Elasticsearch i to ona odpowiedzialna jest za to jak wygląda wykorzystywany przez niego indeks dokumentów.
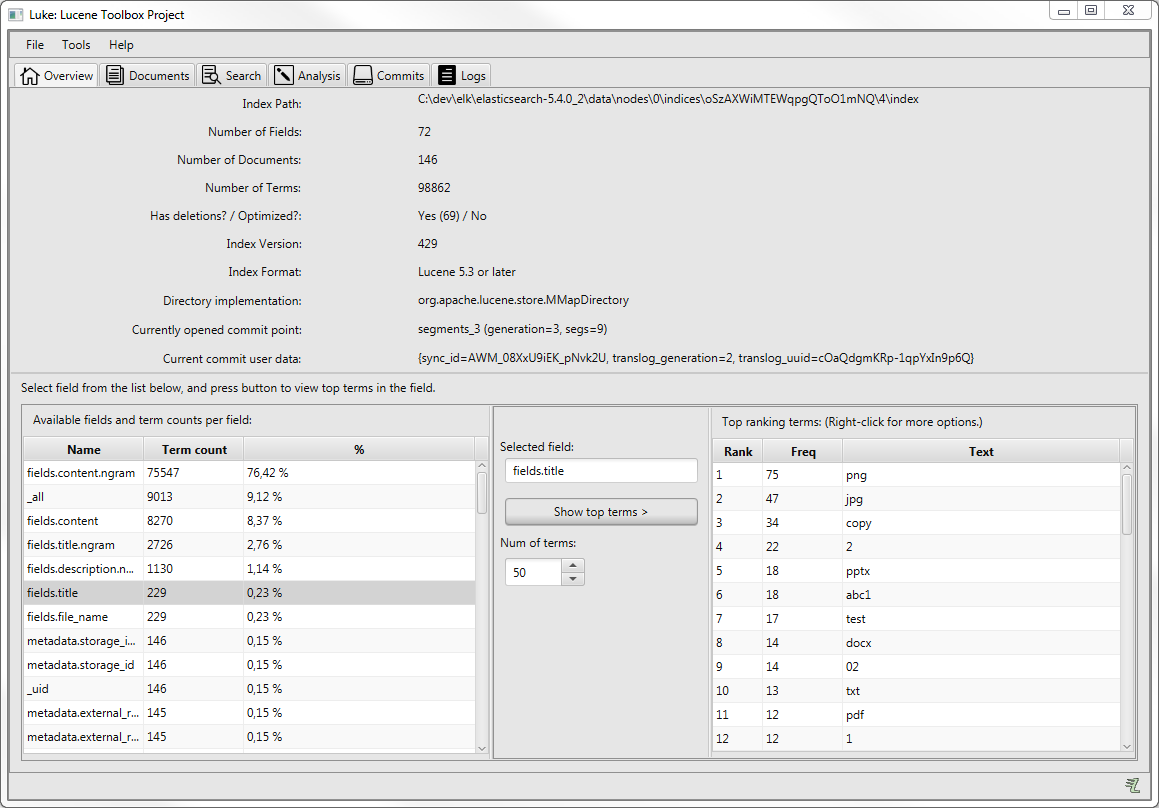
Luke: Lucene Toolbox Project
Kiedy zależy nam, żeby zobaczyć jak taki indeks wygląda wewnątrz i czy został zbudowany po naszej myśli, to Luke nadaje się do tego idealnie. Dodatkowo pozwala również sprawdzić m.in. jak zachowują się poszczególne analizatory Apache Lucene (na których oparte są analizatory Elasticsearcha).
Trzeba otwarcie przyznać, że UI nie jest tu najładniejszy (chociaż to co widzicie powyżej, to jest już odświeżona wersja), a UX miejscami mocno kuleje. Nie ma jednak tutaj kogo za bardzo obwiniać. Program istnieje ładnych parę lat i tułał się przez ten czas od programisty do programisty. Z tego powodu w internecie można znaleźć go w wielu różnych miejscach (wersjonowanego na kilka różnych sposobów). Ostatnio Dmitry Kan stara się nadać projektowi jeden spójny kierunek. Mam nadzieję, że się mu to uda, bo nie znalazłem do tej pory niczego co mogłoby się z Lukiem równać.
UPDATE [2020-07-29]
Przeglądając internet pod kątem innego artykułu trafiłem na dwa narzędzia wyglądające na konkurencję dla ElasticSearch Head:
Sam nie miałem okazji potestować, ale chciałem zaznaczyć, że pojawiają się alternatywy.
The End
To tyle. Te trzy narzędzia będą nam towarzyszyły w kolejnych odcinkach tej serii. Z całą pewnością nie wszystkie za każdym razem, ale warto wiedzieć co mamy do dyspozycji. Ich znajomość przyda Ci się również w komercyjnych projektach.
Bądź na bieżąco!
Podobają Ci się treści publikowane na moim blogu? Nie chcesz niczego pominąć? Zachęcam Cię do subskrybowania kanału RSS, polubienia fanpage na Facebooku, zapisania się na listę mailingową:
lub śledzenia mnie na Twitterze. Generalnie polecam wykonanie wszystkich tych czynności, bo często zdarza się tak, że daną treść wrzucam tylko w jedno miejsce. Zawsze możesz zrobić to na próbę, a jeśli Ci się nie spodoba – zrezygnować 
Dołącz do grup na Facebooku
Chcesz więcej? W takim razie zapraszam Cię do dołączenia do powiązanych grup na Facebooku, gdzie znajdziesz dodatkowe informacje na poruszane tutaj tematy, możesz podzielić się własnymi doświadczeniami i przemyśleniami, a przede wszystkim poznasz ludzi interesujących się tą samą tematyką co Ty.
W grupie Programista Na Swoim znajdziesz wiele doświadczonych osób chętnych do porozmawiania na tematy krążące wokół samozatrudnienia i prowadzenia programistycznej działalności gospodarczej. Vademecum Juniora przeznaczone jest zaś do wymiany wiedzy i doświadczeń na temat życia, kariery i problemów (niekoniecznie młodego) programisty.
Wesprzyj mnie
Jeżeli znalezione tutaj treści sprawiły, że masz ochotę wesprzeć moją działalność online, to zobacz na ile różnych sposobów możesz to zrobić. Niezależnie od tego co wybierzesz, będę Ci za to ogromnie wdzięczny.

Na wsparciu możesz także samemu zyskać. Wystarczy, że rzucisz okiem na listę różnych narzędzi, które używam i polecam. Decydując się na skorzystanie z któregokolwiek linku referencyjnego otrzymasz bonus również dla siebie.
Picture Credits





{kind=link}
18 czerwca 2019 at 12:59
Jakiego polecasz klienta do elasticSearcha do użycia w javie lub kotlinie?
18 czerwca 2019 at 13:41
Dobre pytanie 🙂 ale całkiem dobrze trafiłeś, bo testowałem w boju trzy najbardziej popularne.
Rekomendowałbym Java High Level REST Client, który zastępuje starszego Transport Client-a. Korzystałem w obu wersjach. API z punktu widzenia programisty jest bardzo podobne w obu wersjach. Ma fluent API i pozwala wykorzystać pełen potencjał jaki daje Elasticsearch z różnego wariacjami zapytań, boostingiem, fuzzingiem itp. Wygląda to praktycznie tak jakbyś korzystał z Elasticsearcha, ale pisząc w Javie. Jest to oficjalny klient dostarczany przez firmę Elastic.
Jedna uwaga odnośnie Transport Client-a. Aktualnie nie da się z niego skorzystać z Elasticsearchem hostowanym przez AWS-a. Zgodnie z dokumentacją: The service supports HTTP on port 80, but does not support TCP transport.. Dlatego w tym przypadku pozostaje Java High Level REST Client.
Alternatywą, również od firmy Elastic, jest Java Low Level REST Client, ale jak sama nazwa wskazuje jest „low” – trzeba wiedzieć pod jaki endpoint się odezwać, jaką metodę HTTP wywołać i trzeba rzeźbić każdy request praktycznie ręcznie. Działałem z tym raz na produkcji. Działało, ale każda poprawka sprawiała mi ból 🙂
Jest jeszcze Spring Data Elasticsearch, z którego również próbowałem korzystać. Tylko, że jest przy nim dużo „ALE”. Po pierwsze nie jest on pod pełną kuratelą Pivotala, a „jedynie” projektem community. To w dużej mierze pociąga za sobą fakt, że nie bardzo nadąża za kolejnymi wersjami Elasticsearcha. Drugą kwestią jest to, że (z tego co zdążyłem się zorientować) służy on raczej do mapowania tego co siedzi w Elasticsearchu na obiekty Javy i udostępnia jakieś predefiniowane repozytoria. Wygląda to tak jak większość innych projektów Spring Data XYZ. Minus jest taki, że ogranicza to potencjał drzemiący w Elasticsearchu i nie pozwala na korzystanie z bardziej skomplikowanych zapytań. IMHO Spring Data Elasticsearch w tym momencie nadaje się na do części CRUD-owej, ale nie do skomplikowanych zapytań, które byłyby przyjazne dla użytkownika.
Z tego co widzę jest jeszcze kilka klientów Java i Kotlin od community, ale z żadnego nie korzystałem.
19 czerwca 2019 at 07:07
Dzięki za podsumowanie! Mój research dał mi podobne wyniki i zdecydowałem się na wybór Java High Level REST Client 😉